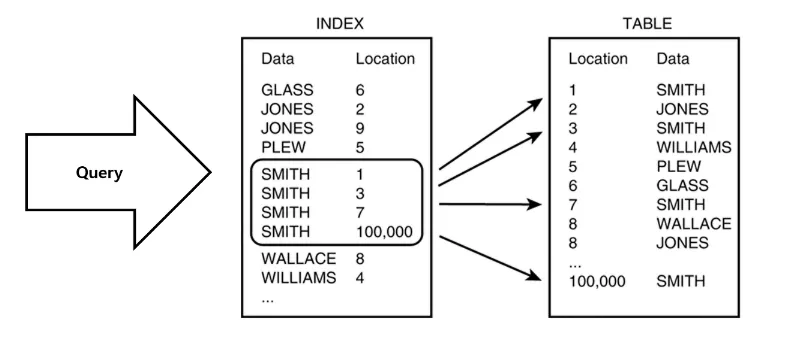
인덱스란?
인덱스는 추가적인 쓰기작업과 저장공간을 사용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
인덱스의 대한 오해
인덱스가 있으면 무조건 UPDATE, DELETE 성능이 떨어진다?
UPDATE, DELETE를 하기 위해서는 해당 row를 찾아야 한다.
따라서, UPDATE나 DELETE를 할 때 조건을 인덱스가 걸려있는 컬럼을 기준으로 찾는다면 성능이 향상 될 수도 있다.
하지만 결국 인덱스를 갱신해야 하는 추가적인 오버헤드가 발생한다.
인덱스의 장 단점
장점
•
테이블을 조회하는 성능을 향상시킬 수 있다.
•
시스템의 전반적인 부하를 줄일 수 있다.
단점
•
인덱스를 저장하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.
•
인덱스를 관리하기 위한 추가작업이 필요하다.
•
인덱스를 잘못 사용하 경우 오히려 성능 저하로 이어진다.
인덱스를 사용해야 하는 경우
1.
WHERE 절에 자주 사용되는 컬럼
2.
JOIN에 자주 사용되는 컬럼
3.
중복 값이 적은 컬럼 (하지만 카디널리티가 낮은 컬럼에도 효과적일 경우가 있다)
인덱스의 동작 원리
인덱스는 일반적으로 B+트리 또는 해시 구조를 사용하여 구현한다.
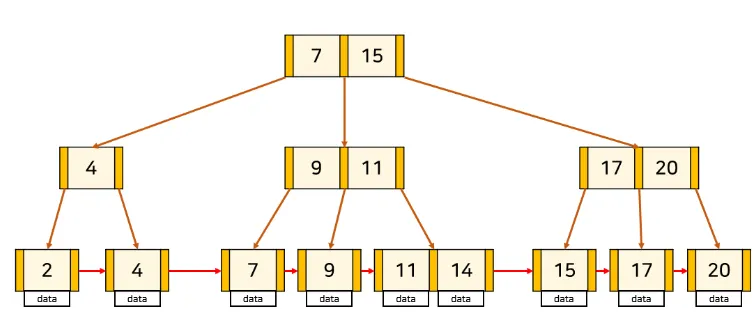
B+트리 구조
Leaf Node는 인덱스와 함께 데이터를 가지고 있고
나머지 Root Node와 Branch Node는 데이터를 위한 인덱스(Key)만 가지고 있다.
Leaf Node끼리는 LinkedList로 연결되어 있어 선형 시간이 소모되어 효율성이 올라간다. (범위 검색에도 알맞음)
Root Node에서 경로를 확인하고 알맞는 경로로 이동하여 원하는 Leaf Node를 탐색한다.
리프 노드가 연결 리스트로 이어져 있기 때문에 특정 범위 내의 데이터를 빠르게 검색할 수 있고
트리의 모든 리프 노드가 동일한 depth를 가지기 때문에 균일한 시간 복잡도를 보장한다.
한 노드에 많은 키를 저장할 수 있으므로 저장공간에서도 장점을 보인다.
시간 복잡도 : O(log n)
해시 구조
해시 테이블 구조는 컬럼의 값과 물리적 주소를 (key, value)의 한 쌍으로 저장하는 자료구조이다.
하지만 해시 테이블은 실제로 인덱스에서 잘 사용하지 않는다.
해시 테이블 구조는 =연산에 최적화되어있고 부등호 연산(범위 연산)에서는 효율적이지 못하기 때문이다
→ 해시 테이블 내의 데이터들은 정렬되어 있지 않으므로 범위 연산에서는 빠르지 않다.
평균적으로 O(1)의 시간 복잡도를 가지기 때문에 매우 빠른 검색과 삽입이 가능하지만
해시 함수의 성능에 따라 충돌이 발생할 수 있으며 충돌은 성능 저하로 이어진다.
해시 함수 테이블의 크기를 잘 조절하지 않으면 저장공간 낭비로 이어진다.
시간 복잡도 : O(1)