


Redis (Remote Dictionary Server)
Redis는 Key-Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈소스 기반의 NoSQL DBMS이다.
Redis를 데이터베이스로 사용할 수도 있고, Cache Server로 사용할 수도 있다.
→ NoSQL 방식 DBMS로 분류되기도 하고, In Memory 솔루션으로 분류되기도 한다.
가장 큰 특징은 In-Memory 데이터 구조 저장소로 데이터를 빠르게 처리할 수 있다.
싱글 스레드 방식을 사용하여 한 번에 하나의 명령어만을 처리하기 때문에 경쟁상태가 거의 발생하지 않는다.
Redis를 사용하는 이유
•
Redis의 가장 큰 특징인 In-Memory구조이기 때문에 매우 빠른 속도로 데이터를 처리할 수 있다.
•
데이터베이스에 가해지는 부하를 감소하고 서비스의 속도를 향상시킬 수 있다.
•
매번 데이터베이스에 접근하여 데이터를 조회하는 경우 Cache Server로 사용을 고려해 볼 수 있고 Redis에서 저장된 값을 그대로 반환하여 사용할 수 있다.
•
Redis의 데이터는 다양한 데이터 타입을 지원하여 애플리케이션 요구 사항에 맞는 다양한 데이터 타입을 활용할 수 있다.
•
Redis는 싱글 스레드이기 때문에 모든 자료구조가 Atomic하기 때문에 데이터의 정합성을 보장하기도 좋다.
Redis의 여러 자료구조
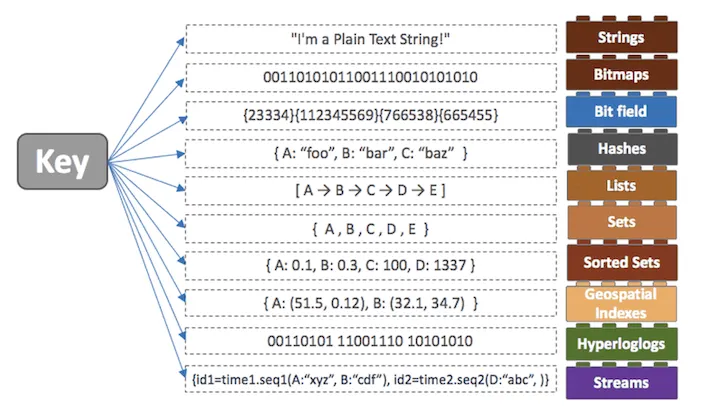
Redis에서 자주 쓰는 자료구조만 정리해 보았다.
•
Hash
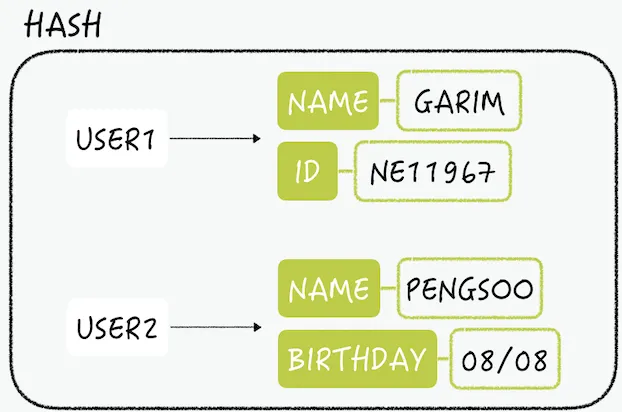
field-value 쌍을 사용한 자료구조
key에 대한 filed의 개수는 제한이 없다.
RDB와 유사 key(USER1)은 RDB 하나의 row와 같다.
•
Set
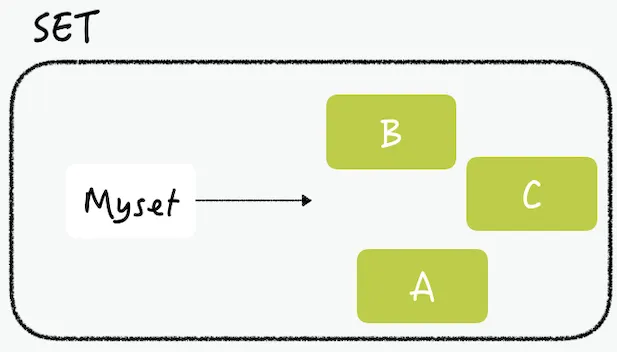
정렬되지 않은 문자열의 모음, 중복될 수 없다.
교집합, 차집합, 합집합 등 연산을 레디스에서 수행할 수 있다.
•
Sorted Set
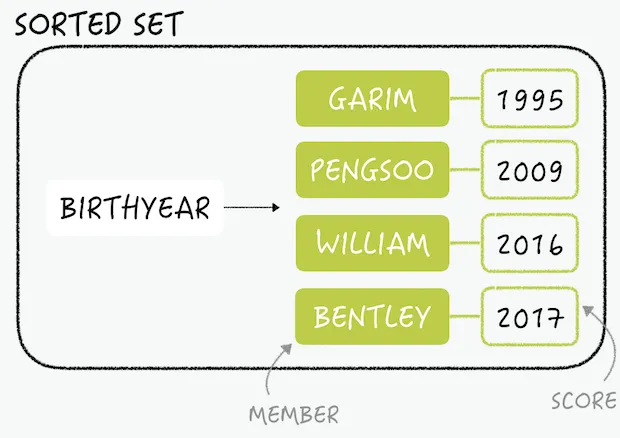
set과 마찬가지로 key 하나에 중복되지 않은 여러 멤버를 저장하지만 각각의 멤버는 SCORE에 연결된다.
모든 데이터는 SCORE로 정렬되며 주로 sort가 필요한 곳에 사용된다.
Redis 사용시 주의할 점
•
Redis는 싱글 스레드 기반이기 때문에 한 요청을 수행하는 동안 다른 요청을 받지 못한다.
◦
한 클라이언트가 많은 시간을 소모하는 요청을 할 경우 장애가 발생할 수 있다.
•
하나의 key에 너무 많은 데이터를 적재하지 않도록 한다.
•
TTL timeout 적절한 값을 설정해야 한다.
Redis의 ZSet
Redis는 key-value 타입의 자료 저장 형태를 제공한다. 거기에 추가로 ZSET이라는 특이한 형태의 저장 형태를 제공한다.
ZSET은 일반적인 Set 자료구조와 유사하지만 각 요소에 점수(Score)를 할당 할 수 있고, 이 점수에 따라 자동으로 정렬되는 특성을 가지고 있다.
ZSET의 특징
•
요소와 점수로 이루어진 구조
◦
ZSET의 요소(Member)는 고유한 점수(Score)와 함께 저장된다. Score는 double 타입의 실수이고 요소의 정렬 기준이 된다.
•
중복 없음
◦
ZSET 내의 요소(Member)는 유일해야 하며, 중복된 요소(Member)를 추가하면 Score만 갱신된다.
•
자동 정렬
◦
ZSET은 요소들이 점수에 따라 정렬된다. 기본적으로 점수가 낮은 순으로 정렬되지만 높은 순서대로 조회할 수도 있다.
보통 RDBMS에서는 정렬이 필요한 컬럼을 index를 이용하여 정렬할 수 있지만, 하나의 테이블에 미리 인덱싱을 해줄 수 있는 Clustered Index는 하나만 생성할 수 있다. 다른 컬럼에 대해서 인덱싱이 필요한 경우에는 Non-Clustered Index를 사용하게 되는데 이는 조회하는 순간 부하가 커지고 속도가 느려지는 현상이 일어난다.
하지만, ZSET은 Sorted Set을 이용하여 구현했기때문에 랭킹 등 인덱싱이 필요한 기능을 처리하는데 알맞는 자료구조이다.
